An LLM on a Sony PSP
A Sony PSP-2000 is a 333 MHz MIPS handheld from 2007 with 64 MB of RAM. Mine, this week, runs a 15-million-parameter Transformer and streams English text onto the LCD at one to two tokens per second.
The model is Karpathy’s stories15M (a TinyStories checkpoint), int8-quantized to about 17 MB. The runtime is ~1100 lines of pure C cross-compiled with pspdev/pspdev in Docker. There is no Python, no libtorch, no helpful runtime on the device — the PSP is a single-process box that loads one EBOOT.PBP from the memory stick and gives you sceIo*, a framebuffer, and a VFPU. Everything else you build.
This post is the budget. Where every byte goes, what the kernels look like, and what’s left on the table.
The hardware
| CPU | MIPS Allegrex @ 333 MHz, in-order |
| FPU | scalar fp32 + a 4×4 VFPU (vector) coprocessor |
| RAM | 64 MB (PSP-2000/3000); 32 MB on the original PSP-1000 |
| OS | XMB, no virtual memory, no mmap, no swap |
| Output | 480×272 LCD, no stdout the host can read |
The “no mmap” line is the one that bites. On a Linux box you’d mmap the weights file and let the page cache handle it. On the PSP you have sceIoLseek + sceIoRead and a single malloc’d arena. You read all 17 MB into RAM before forward pass #1, or you stream from the memory stick at roughly the speed of a USB 1.1 thumb drive and watch your throughput collapse.
The PSP-1000’s 32 MB is not enough to leave heap room for the weights plus KV cache plus working buffers. The 2000 and 3000 ship with 64 MB. We need the 64.
The model
stories15M is the smallest of Karpathy’s TinyStories checkpoints — 6 transformer layers, hidden size 288, 6 attention heads, vocab 32000. About fifteen million parameters total. At fp32, ~57 MB. At int8 q80 — symmetric per-group quantization, group size 64, one fp32 scale per group — ~17 MB.
Architecture: Llama-style decoder, RoPE, SwiGLU FFN
Layers: 6
Hidden: 288
Heads: 6 (head_dim 48)
Vocab: 32000
Context: 256 tokens
Quantization: int8 q80 (group=64, symmetric)
On-disk size: 17 MB
The model prep is its own Docker image: python:3.11-slim + cpu-only torch + a pinned commit of karpathy/llama2.c. It downloads stories15M.pt, runs export.py --version 2 to produce the q80 model.bin, builds the BPE tokenizer.bin, and — important — also builds Karpathy’s runq.c reference with -ffp-contract=off -fno-fast-math and runs it on a fixed prompt to produce tests/expected.txt. That file is the byte-exact x86 reference the PSP gets diffed against. More on this in a minute.
The memory budget
24 MB of heap, declared once at module load:
PSP_HEAP_SIZE_KB(24576);
Spent as:
| Region | Size | Notes |
|---|---|---|
| Weights (int8 quantized) | ~17 MB | single malloc’d arena, slurped via sceIoLseek + sceIoRead chunks |
| KV cache | ~3.5 MB | 6 layers × 256 ctx × 288 hidden × 2 (K+V) × fp32 |
RunState working buffers | ~1 MB | activations, attention scores, sampled logits |
| Stack, libc, framework | ~2 MB | the PSPSDK’s overhead |
| Slack | ~0.5 MB |
The trick worth calling out: the token embedding table stays quantized in the arena. The naive port dequantizes it once at load time, which costs ~36 MB and immediately OOMs. Instead, on each forward we dequantize a single row — the row for the current token — into a small fp32 buffer. The cost is one extra dequant per forward; the win is ~36 MB we don’t have.
The kernels
transformer.c is the usual suspects: rmsnorm, softmax, quantize/dequantize, matmul, RoPE, attention, SwiGLU, sampler. Each one is the textbook version with -ffp-contract=off forced so the order of multiply-add operations matches runq.c on x86. That matters for the test surface (see below).
The matmul today is scalar fp32 — three nested loops, one fp32 multiply-add at a time. On real hardware it gets ~1–2 tok/s. That’s slow enough that a 64-token completion takes about a minute.
The matmul is also factored as a swappable function pointer. The v1 plan is a VFPU kernel that uses the 4×4 vector ops, which should hit ~5–15 tok/s on the same hardware. (The VFPU is the one piece of PSP hardware that ages well — a vector coprocessor with 128 registers addressable as eight 4×4 matrices, capable of dispatching a 4×4 matrix multiply in a single instruction.) That’s a one-file change to drop in.
The UI
The PSP has a system on-screen keyboard you invoke via sceUtilityOsk*. It returns text as UTF-16LE; you convert it to UTF-8 (BMP only — the PSP’s OSK doesn’t reach into surrogate pairs) and feed it to the BPE tokenizer.
The chat UI is pspDebugScreen — the PSP’s built-in debug font on the framebuffer. Monospace, 8×8 pixels, 60 columns × 34 rows on the 480×272 display. Two-color layout: the prompt at the top, generated tokens streaming below it character by character. When the buffer hits the bottom of the screen the rendering wraps. It’s not pretty, but it’s legible, and every character on the screen is something the model actually emitted.
The demo
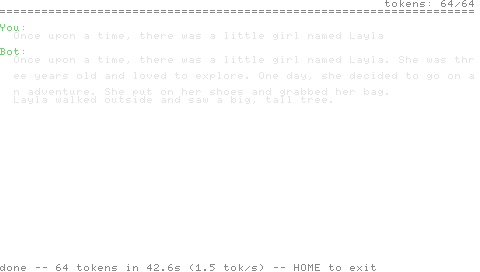
Prompt:
Once upon a time, there was a little girl named Layla
Generated (T=0, 64 tokens):
She was three years old and loved to explore. One day, she decided to go on an adventure. She put on her shoes and grabbed her bag. Layla walked outside and saw a big, tall tree.
That output is identical, byte for byte, to what runq.c produces on x86_64 with the same model, the same prompt, the same temperature, and matching FP flags. That equivalence is the test surface — diff -q state.txt tests/expected.txt either returns clean or every layer of the inference engine is wrong. It is much stronger than the OCR-based tests the earlier Pong build in this same repo shipped on; the screen on the PSP is decorative now, and the truth is a text file on the emulated memory stick.
Sideloading to real hardware
Everything above runs under PPSSPP in the test loop. To put it on metal:
PSP/
└── GAME/
└── PspLlm/
├── EBOOT.PBP
├── model.bin
└── tokenizer.bin
Drop the three files onto the memory stick, browse to the game in the XMB, hit X. PSP-2000 or PSP-3000 only — PSP-1000’s 32 MB doesn’t leave heap room — and the PSP needs custom firmware to run unsigned EBOOT.PBP (6.61 PRO-C2 or 6.61 Infinity on a PSP; Adrenaline on a PS Vita). Cold start to OSK is about three seconds. First-token latency depends almost entirely on prompt length; per-token after that is the matmul.
What’s next
| Item | Why | Expected impact |
|---|---|---|
| VFPU matmul | scalar fp32 leaves the only good vector unit on the chip idle | ~5–15 tok/s instead of 1–2 |
| Multi-turn KV retention | every prompt today re-fills the KV cache from zero | usable chat instead of one-shot continuations |
stories42M | fits at ~21 MB quantized; still inside 24 MB heap | richer outputs, same UI |
stories110M | won’t fit; needs weight streaming from memory stick | probably not worth the throughput hit |
The constraint isn’t compute — the VFPU upgrade pays back an order of magnitude. The constraint is RAM. 64 MB is the budget, and once you’ve paid for the OS, the heap, the KV cache, and the working buffers, you have exactly enough room for a 17 MB model and not a byte more. Sony shipped this hardware to play MP3s and run Wipeout. Every other LLM I’ve used this week ran on a GPU that cost more than the PSP did. This one runs on the PSP.