Un LLM en una Sony PSP
Una Sony PSP-2000 es un dispositivo portátil MIPS de 333 MHz del año 2007 con 64 MB de RAM. La mía, esta semana, ejecuta un Transformer de 15 millones de parámetros y transmite texto en inglés a la pantalla LCD a uno o dos tokens por segundo.
El modelo es stories15M de Karpathy (un checkpoint de TinyStories), cuantizado a int8 a unos 17 MB. El runtime son ~1100 líneas de C puro compilado cruzado con pspdev/pspdev en Docker. No hay Python, no hay libtorch, no hay ningún runtime de ayuda en el dispositivo — la PSP es una caja de proceso único que carga un único EBOOT.PBP desde el memory stick y te da sceIo*, un framebuffer y una VFPU. Todo lo demás lo construyes tú.
Este post es el presupuesto. Dónde va cada byte, cómo son los kernels, y qué queda sobre la mesa.
El hardware
| CPU | MIPS Allegrex @ 333 MHz, en orden |
| FPU | fp32 escalar + coprocesador VFPU (vectorial) 4×4 |
| RAM | 64 MB (PSP-2000/3000); 32 MB en la PSP-1000 original |
| OS | XMB, sin memoria virtual, sin mmap, sin swap |
| Salida | LCD 480×272, sin stdout que pueda leer el host |
La línea “sin mmap” es la que duele. En una máquina Linux harías mmap del archivo de pesos y dejarías que la caché de páginas lo gestionara. En la PSP tienes sceIoLseek + sceIoRead y una única arena asignada con malloc. Lees los 17 MB completos en RAM antes del primer forward pass, o haces streaming desde el memory stick a la velocidad aproximada de un pendrive USB 1.1 y ves cómo tu rendimiento se desploma.
Los 32 MB de la PSP-1000 no son suficientes para dejar espacio de heap para los pesos, la caché KV y los buffers de trabajo. Los modelos 2000 y 3000 traen 64 MB. Necesitamos los 64.
El modelo
stories15M es el menor de los checkpoints TinyStories de Karpathy — 6 capas transformer, tamaño oculto 288, 6 cabezas de atención, vocabulario de 32000. Unos quince millones de parámetros en total. En fp32, ~57 MB. En int8 q80 — cuantización simétrica por grupo, tamaño de grupo 64, una escala fp32 por grupo — ~17 MB.
Arquitectura: Decodificador estilo Llama, RoPE, SwiGLU FFN
Capas: 6
Oculto: 288
Cabezas: 6 (head_dim 48)
Vocabulario: 32000
Contexto: 256 tokens
Cuantización: int8 q80 (group=64, simétrico)
Tamaño en disco: 17 MB
La preparación del modelo es su propia imagen Docker: python:3.11-slim + torch solo para CPU + un commit fijado de karpathy/llama2.c. Descarga stories15M.pt, ejecuta export.py --version 2 para producir el model.bin q80, construye el tokenizer.bin BPE, y — importante — también construye la referencia runq.c de Karpathy con -ffp-contract=off -fno-fast-math y la ejecuta con un prompt fijo para producir tests/expected.txt. Ese archivo es la referencia x86 exacta al byte contra la que se compara la PSP. Más sobre esto en un momento.
El presupuesto de memoria
24 MB de heap, declarados una vez al cargar el módulo:
PSP_HEAP_SIZE_KB(24576);
Distribuidos así:
| Región | Tamaño | Notas |
|---|---|---|
| Pesos (cuantizados int8) | ~17 MB | arena única con malloc, leída en chunks con sceIoLseek + sceIoRead |
| Caché KV | ~3,5 MB | 6 capas × 256 ctx × 288 oculto × 2 (K+V) × fp32 |
Buffers de trabajo RunState | ~1 MB | activaciones, puntuaciones de atención, logits muestreados |
| Stack, libc, framework | ~2 MB | overhead del PSPSDK |
| Margen | ~0,5 MB |
El truco que merece destacarse: la tabla de embeddings de tokens permanece cuantizada en la arena. La implementación ingenua la descuantiza de una vez al cargar, lo que cuesta ~36 MB y provoca inmediatamente OOM. En cambio, en cada forward descuantizamos una sola fila — la fila del token actual — en un pequeño buffer fp32. El coste es una descuantización extra por forward; la ganancia es ~36 MB que no tenemos.
Los kernels
transformer.c es la lista habitual: rmsnorm, softmax, quantize/dequantize, matmul, RoPE, atención, SwiGLU, muestreador. Cada uno es la versión del libro de texto con -ffp-contract=off forzado para que el orden de las operaciones multiply-add coincida con runq.c en x86. Eso importa para la superficie de prueba (ver más abajo).
El matmul hoy es fp32 escalar — tres bucles anidados, una operación multiply-add fp32 a la vez. En hardware real alcanza ~1–2 tok/s. Eso es suficientemente lento como para que una completación de 64 tokens tarde unos un minuto.
El matmul también está factorizado como un puntero de función intercambiable. El plan v1 es un kernel VFPU que usa las operaciones vectoriales 4×4, que debería alcanzar ~5–15 tok/s en el mismo hardware. (La VFPU es la pieza del hardware PSP que envejece mejor — un coprocesador vectorial con 128 registros direccionables como ocho matrices 4×4, capaz de despachar una multiplicación de matrices 4×4 en una sola instrucción.) Ese es un cambio de un solo archivo para incorporarlo.
La interfaz de usuario
La PSP tiene un teclado en pantalla del sistema que se invoca mediante sceUtilityOsk*. Devuelve texto como UTF-16LE; lo conviertes a UTF-8 (solo BMP — el OSK de la PSP no llega a los pares sustitutos) y lo alimentas al tokenizador BPE.
La interfaz de chat es pspDebugScreen — la fuente de depuración integrada de la PSP sobre el framebuffer. Monospace, 8×8 píxeles, 60 columnas × 34 filas en la pantalla 480×272. Diseño de dos colores: el prompt en la parte superior, los tokens generados fluyendo debajo carácter a carácter. Cuando el buffer llega al fondo de la pantalla, el renderizado se envuelve. No es bonito, pero es legible, y cada carácter en la pantalla es algo que el modelo realmente emitió.
La demo
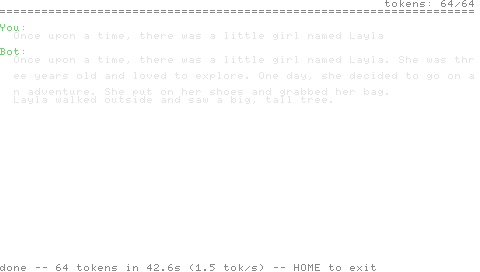
Prompt:
Once upon a time, there was a little girl named Layla
Generado (T=0, 64 tokens):
She was three years old and loved to explore. One day, she decided to go on an adventure. She put on her shoes and grabbed her bag. Layla walked outside and saw a big, tall tree.
Esa salida es idéntica, byte por byte, a lo que runq.c produce en x86_64 con el mismo modelo, el mismo prompt, la misma temperatura y los mismos flags de FP. Esa equivalencia es la superficie de prueba — diff -q state.txt tests/expected.txt devuelve limpio o cada capa del motor de inferencia está mal. Es mucho más robusto que las pruebas basadas en OCR que el build anterior de Pong en este mismo repositorio publicó; la pantalla en la PSP es ahora decorativa, y la verdad es un archivo de texto en el memory stick emulado.
Carga lateral al hardware real
Todo lo anterior se ejecuta bajo PPSSPP en el bucle de prueba. Para ponerlo en metal:
PSP/
└── GAME/
└── PspLlm/
├── EBOOT.PBP
├── model.bin
└── tokenizer.bin
Coloca los tres archivos en el memory stick, navega al juego en el XMB, pulsa X. Solo PSP-2000 o PSP-3000 — los 32 MB de la PSP-1000 no dejan espacio de heap — y la PSP necesita firmware personalizado para ejecutar EBOOT.PBP sin firmar (6.61 PRO-C2 o 6.61 Infinity en una PSP; Adrenaline en una PS Vita). El arranque en frío hasta el OSK tarda unos tres segundos. La latencia del primer token depende casi totalmente de la longitud del prompt; el tiempo por token después de eso es el matmul.
Qué viene después
| Elemento | Por qué | Impacto esperado |
|---|---|---|
| Matmul VFPU | el fp32 escalar deja la única buena unidad vectorial del chip inactiva | ~5–15 tok/s en lugar de 1–2 |
| Retención KV multi-turno | cada prompt hoy rellena la caché KV desde cero | chat usable en lugar de continuaciones de un solo disparo |
stories42M | cabe en ~21 MB cuantizado; sigue dentro del heap de 24 MB | salidas más ricas, misma interfaz |
stories110M | no cabe; necesita streaming de pesos desde el memory stick | probablemente no vale la pena el impacto en el rendimiento |
La restricción no es el cómputo — la mejora de la VFPU devuelve un orden de magnitud. La restricción es la RAM. 64 MB es el presupuesto, y una vez que has pagado por el OS, el heap, la caché KV y los buffers de trabajo, tienes exactamente espacio suficiente para un modelo de 17 MB y ni un byte más. Sony fabricó este hardware para reproducir MP3s y ejecutar Wipeout. Todos los demás LLM que he usado esta semana funcionaban en una GPU que costaba más que la PSP. Este funciona en la PSP.