Un LLM su una Sony PSP
Una Sony PSP-2000 è un portatile MIPS da 333 MHz del 2007 con 64 MB di RAM. La mia, questa settimana, esegue un Transformer da 15 milioni di parametri e trasmette testo in inglese sul display LCD a uno o due token al secondo.
Il modello è il stories15M di Karpathy (un checkpoint TinyStories), quantizzato int8 a circa 17 MB. Il runtime sono ~1100 righe di C puro cross-compilato con pspdev/pspdev in Docker. Niente Python, niente libtorch, nessun runtime utile sul dispositivo — la PSP è una scatola a singolo processo che carica un unico EBOOT.PBP dalla memory stick e ti dà sceIo*, un framebuffer e una VFPU. Tutto il resto lo costruisci tu.
Questo post è il budget. Dove va ogni byte, come appaiono i kernel e cosa rimane sul tavolo.
L’hardware
| CPU | MIPS Allegrex @ 333 MHz, in-order |
| FPU | fp32 scalare + un coprocessore VFPU (vettoriale) 4×4 |
| RAM | 64 MB (PSP-2000/3000); 32 MB sulla PSP-1000 originale |
| OS | XMB, nessuna memoria virtuale, nessun mmap, nessun swap |
| Output | LCD 480×272, nessun stdout leggibile dall’host |
La riga “nessun mmap” è quella che fa male. Su un sistema Linux faresti mmap del file dei pesi e lasceresti che la page cache lo gestisse. Sulla PSP hai sceIoLseek + sceIoRead e un’unica arena allocata con malloc. Leggi tutti i 17 MB in RAM prima del forward pass #1, oppure fai streaming dalla memory stick alla velocità approssimativa di una chiavetta USB 1.1 e guardi il tuo throughput crollare.
I 32 MB della PSP-1000 non sono sufficienti per lasciare spazio heap per i pesi più la cache KV più i buffer di lavoro. I modelli 2000 e 3000 hanno 64 MB. Abbiamo bisogno dei 64.
Il modello
stories15M è il più piccolo dei checkpoint TinyStories di Karpathy — 6 layer transformer, dimensione nascosta 288, 6 teste di attenzione, vocabolario 32000. Circa quindici milioni di parametri in totale. In fp32, ~57 MB. In int8 q80 — quantizzazione simmetrica per gruppo, dimensione del gruppo 64, una scala fp32 per gruppo — ~17 MB.
Architettura: Decoder stile Llama, RoPE, SwiGLU FFN
Layer: 6
Nascosto: 288
Teste: 6 (head_dim 48)
Vocabolario: 32000
Contesto: 256 token
Quantizzazione: int8 q80 (group=64, simmetrico)
Dimensione disco: 17 MB
La preparazione del modello è la sua propria immagine Docker: python:3.11-slim + torch solo cpu + un commit fissato di karpathy/llama2.c. Scarica stories15M.pt, esegue export.py --version 2 per produrre il model.bin q80, costruisce il tokenizer.bin BPE, e — importante — costruisce anche il riferimento runq.c di Karpathy con -ffp-contract=off -fno-fast-math e lo esegue su un prompt fisso per produrre tests/expected.txt. Quel file è il riferimento x86 esatto al byte con cui la PSP viene confrontata. Più su questo tra un momento.
Il budget di memoria
24 MB di heap, dichiarati una volta al caricamento del modulo:
PSP_HEAP_SIZE_KB(24576);
Distribuiti così:
| Regione | Dimensione | Note |
|---|---|---|
| Pesi (quantizzati int8) | ~17 MB | arena singola con malloc, letta in chunk via sceIoLseek + sceIoRead |
| Cache KV | ~3,5 MB | 6 layer × 256 ctx × 288 hidden × 2 (K+V) × fp32 |
Buffer di lavoro RunState | ~1 MB | attivazioni, punteggi di attenzione, logit campionati |
| Stack, libc, framework | ~2 MB | overhead del PSPSDK |
| Margine | ~0,5 MB |
Il trucco che vale la pena evidenziare: la tabella degli embedding dei token rimane quantizzata nell’arena. La port ingenua la dequantizza una volta al caricamento, il che costa ~36 MB e causa immediatamente OOM. Invece, ad ogni forward dequantizziamo una singola riga — la riga per il token corrente — in un piccolo buffer fp32. Il costo è una dequantizzazione extra per forward; il guadagno è ~36 MB che non abbiamo.
I kernel
transformer.c è la lista dei soliti: rmsnorm, softmax, quantize/dequantize, matmul, RoPE, attenzione, SwiGLU, sampler. Ognuno è la versione del manuale con -ffp-contract=off forzato in modo che l’ordine delle operazioni multiply-add corrisponda a runq.c su x86. Questo è importante per la superficie di test (vedi sotto).
Il matmul oggi è fp32 scalare — tre cicli annidati, una moltiplicazione-addizione fp32 alla volta. Su hardware reale raggiunge ~1–2 tok/s. È abbastanza lento da far durare un completamento da 64 token circa un minuto.
Il matmul è anche fattorizzato come puntatore a funzione intercambiabile. Il piano v1 è un kernel VFPU che usa le operazioni vettoriali 4×4, che dovrebbe raggiungere ~5–15 tok/s sullo stesso hardware. (La VFPU è l’unico pezzo di hardware PSP che invecchia bene — un coprocessore vettoriale con 128 registri indirizzabili come otto matrici 4×4, capace di eseguire una moltiplicazione di matrici 4×4 in una singola istruzione.) Quello è un cambiamento di un singolo file da inserire.
L’interfaccia utente
La PSP ha una tastiera su schermo di sistema che invochi tramite sceUtilityOsk*. Restituisce testo come UTF-16LE; lo converti in UTF-8 (solo BMP — l’OSK della PSP non raggiunge le coppie surrogate) e lo passi al tokenizer BPE.
La chat UI è pspDebugScreen — il font di debug integrato della PSP sul framebuffer. Monospace, 8×8 pixel, 60 colonne × 34 righe sul display 480×272. Layout bicolore: il prompt in alto, i token generati che scorrono sotto carattere per carattere. Quando il buffer raggiunge il fondo dello schermo, il rendering va a capo. Non è esteticamente bello, ma è leggibile, e ogni carattere sullo schermo è qualcosa che il modello ha effettivamente emesso.
La demo
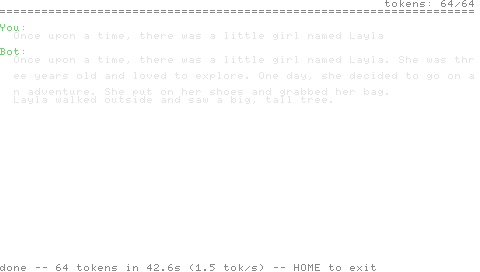
Prompt:
Once upon a time, there was a little girl named Layla
Generato (T=0, 64 token):
She was three years old and loved to explore. One day, she decided to go on an adventure. She put on her shoes and grabbed her bag. Layla walked outside and saw a big, tall tree.
Quell’output è identico, byte per byte, a ciò che runq.c produce su x86_64 con lo stesso modello, lo stesso prompt, la stessa temperatura e i flag FP corrispondenti. Quella equivalenza è la superficie di test — diff -q state.txt tests/expected.txt restituisce pulito oppure ogni layer del motore di inferenza è sbagliato. È molto più forte dei test basati su OCR che la build precedente di Pong nello stesso repo ha spedito; lo schermo sulla PSP è ora decorativo, e la verità è un file di testo sulla memory stick emulata.
Sideloading su hardware reale
Tutto quanto sopra gira sotto PPSSPP nel ciclo di test. Per metterlo su metallo:
PSP/
└── GAME/
└── PspLlm/
├── EBOOT.PBP
├── model.bin
└── tokenizer.bin
Metti i tre file sulla memory stick, sfoglia al gioco nel XMB, premi X. Solo PSP-2000 o PSP-3000 — i 32 MB della PSP-1000 non lasciano spazio heap — e la PSP necessita di firmware personalizzato per eseguire EBOOT.PBP non firmati (6.61 PRO-C2 o 6.61 Infinity su una PSP; Adrenaline su una PS Vita). L’avvio a freddo fino all’OSK è di circa tre secondi. La latenza del primo token dipende quasi interamente dalla lunghezza del prompt; per token dopo di quello è il matmul.
Cosa c’è dopo
| Voce | Perché | Impatto previsto |
|---|---|---|
| Matmul VFPU | l’fp32 scalare lascia l’unica buona unità vettoriale sul chip inattiva | ~5–15 tok/s invece di 1–2 |
| Ritenzione KV multi-turno | ogni prompt oggi riempie la cache KV da zero | chat utilizzabile invece di continuazioni singole |
stories42M | si adatta a ~21 MB quantizzato; ancora dentro i 24 MB di heap | output più ricchi, stessa UI |
stories110M | non si adatta; richiede lo streaming dei pesi dalla memory stick | probabilmente non vale l’impatto sul throughput |
Il vincolo non è la potenza di calcolo — l’aggiornamento VFPU restituisce un ordine di grandezza. Il vincolo è la RAM. 64 MB è il budget, e una volta pagato per il OS, l’heap, la cache KV e i buffer di lavoro, hai esattamente abbastanza spazio per un modello da 17 MB e non un byte di più. Sony ha prodotto questo hardware per riprodurre MP3 e far girare Wipeout. Ogni altro LLM che ho usato questa settimana girava su una GPU che costava più della PSP. Questo gira sulla PSP.