在索尼PSP上运行LLM
索尼PSP-2000是一款2007年的333MHz MIPS掌机,配备64MB内存。这周,我的PSP运行着一个1500万参数的Transformer,以每秒一到两个token的速度将英文文本输出到LCD屏幕。
该模型是Karpathy的stories15M(一个TinyStories检查点),int8量化后约17MB。运行时是约1100行纯C代码,在Docker中使用pspdev/pspdev交叉编译。没有Python,没有libtorch,设备上没有任何辅助运行时——PSP是一个单进程设备,从记忆棒加载一个EBOOT.PBP文件,提供sceIo*、帧缓冲区和VFPU。其余的一切都需要自己构建。
这篇文章就是账单。每个字节去哪儿了,内核是什么样的,还有什么留待完成。
硬件
| CPU | MIPS Allegrex @ 333 MHz,顺序执行 |
| FPU | 标量fp32 + 4×4 VFPU(向量)协处理器 |
| RAM | 64 MB(PSP-2000/3000);原版PSP-1000为32 MB |
| OS | XMB,无虚拟内存,无mmap,无交换分区 |
| 输出 | 480×272 LCD,主机无法读取的stdout |
“无mmap“这一行是最痛的限制。在Linux系统上,你会对权重文件使用mmap并让页面缓存处理。在PSP上,你只有sceIoLseek + sceIoRead和一块用malloc分配的单一内存区。你要在第一次前向传播前将全部17MB读入内存,否则就从记忆棒以USB 1.1闪存盘的速度流式读取,然后看着吞吐量崩溃。
PSP-1000的32MB不足以为权重加KV缓存加工作缓冲区留出足够的堆空间。2000和3000配备64MB。我们需要64MB。
模型
stories15M是Karpathy的TinyStories检查点中最小的——6个Transformer层,隐藏维度288,6个注意力头,词汇表32000。总计约1500万参数。fp32格式约57MB。int8 q80——对称的按组量化,组大小64,每组一个fp32缩放因子——约17MB。
架构: Llama风格解码器,RoPE,SwiGLU FFN
层数: 6
隐藏维度: 288
注意力头: 6 (head_dim 48)
词汇表: 32000
上下文长度: 256 tokens
量化方式: int8 q80 (group=64,对称)
磁盘大小: 17 MB
模型准备工作有自己专用的Docker镜像:python:3.11-slim + 仅CPU版torch + karpathy/llama2.c的固定提交。它下载stories15M.pt,运行export.py --version 2生成q80格式的model.bin,构建BPE的tokenizer.bin,并且——重要的是——还使用-ffp-contract=off -fno-fast-math构建Karpathy的runq.c参考实现,并在固定提示词上运行,生成tests/expected.txt。该文件是PSP进行diff比较的字节精确x86参考输出。稍后详述。
内存预算
24MB堆,在模块加载时声明一次:
PSP_HEAP_SIZE_KB(24576);
分配如下:
| 区域 | 大小 | 备注 |
|---|---|---|
| 权重(int8量化) | ~17 MB | 单一malloc内存区,通过sceIoLseek + sceIoRead分块读取 |
| KV缓存 | ~3.5 MB | 6层 × 256上下文 × 288隐藏 × 2(K+V) × fp32 |
RunState工作缓冲区 | ~1 MB | 激活值、注意力分数、采样的logits |
| 栈、libc、框架 | ~2 MB | PSPSDK的开销 |
| 余量 | ~0.5 MB |
值得特别指出的技巧:token嵌入表在内存区中保持量化状态。朴素的移植会在加载时一次性反量化整个表,这需要约36MB并立即导致OOM。相反,每次前向传播只将当前token对应的单行反量化到一个小型fp32缓冲区。代价是每次前向传播多一次反量化;收益是我们不需要拥有的约36MB。
内核
transformer.c是惯常的那些:rmsnorm、softmax、quantize/dequantize、matmul、RoPE、注意力机制、SwiGLU、采样器。每个都是教科书版本,强制使用-ffp-contract=off以使乘加运算的顺序与x86上的runq.c一致。这对测试验证很重要(见下文)。
当前的matmul是标量fp32——三重嵌套循环,每次一个fp32乘加运算。在真实硬件上达到约1–2 tok/s。这足够慢,64个token的补全大约需要一分钟。
matmul也被设计为可替换的函数指针。v1计划是一个使用4×4向量运算的VFPU内核,应该在同样的硬件上达到约5–15 tok/s。(VFPU是PSP硬件中最经久耐用的部分——一个拥有128个寄存器的向量协处理器,可将其寻址为八个4×4矩阵,能够在单条指令中执行4×4矩阵乘法。)替换只需修改一个文件。
用户界面
PSP有一个通过sceUtilityOsk*调用的系统屏幕键盘。它返回UTF-16LE格式的文本;你将其转换为UTF-8(仅限BMP——PSP的OSK不支持代理对),然后输入BPE分词器。
聊天界面是pspDebugScreen——PSP在帧缓冲区上的内置调试字体。等宽字体,8×8像素,480×272显示屏上60列×34行。双色布局:顶部是提示词,生成的token在下方逐字符流式显示。当缓冲区到达屏幕底部时,渲染换行。不漂亮,但清晰可读,屏幕上的每个字符都是模型实际输出的内容。
演示
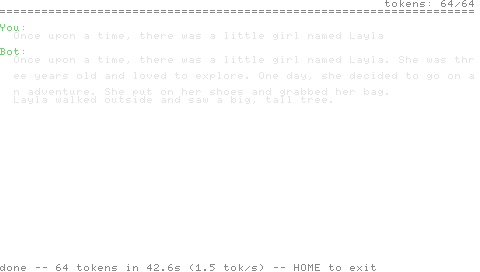
提示词:
Once upon a time, there was a little girl named Layla
生成内容(T=0,64个token):
She was three years old and loved to explore. One day, she decided to go on an adventure. She put on her shoes and grabbed her bag. Layla walked outside and saw a big, tall tree.
该输出与runq.c在x86_64上使用相同模型、相同提示词、相同温度和匹配的FP标志产生的结果在字节层面完全一致。这种等价性就是测试验证面——diff -q state.txt tests/expected.txt要么返回干净,要么推理引擎的每一层都有问题。这比同一仓库中早期Pong构建所采用的基于OCR的测试强大得多;PSP屏幕现在只是装饰,真相是模拟记忆棒上的文本文件。
刷入真机
以上所有内容都在测试循环中的PPSSPP下运行。要在真机上运行:
PSP/
└── GAME/
└── PspLlm/
├── EBOOT.PBP
├── model.bin
└── tokenizer.bin
将三个文件放到记忆棒上,在XMB中找到游戏,按X键。仅支持PSP-2000或PSP-3000——PSP-1000的32MB堆空间不足——PSP需要自定义固件才能运行未签名的EBOOT.PBP(PSP上使用6.61 PRO-C2或6.61 Infinity;PS Vita上使用Adrenaline)。冷启动到OSK大约需要三秒。第一个token的延迟几乎完全取决于提示词长度;之后每个token的时间取决于matmul。
接下来
| 项目 | 原因 | 预期影响 |
|---|---|---|
| VFPU matmul | 标量fp32让芯片上唯一的优质向量单元闲置 | 约5–15 tok/s而非1–2 |
| 多轮KV保留 | 目前每个提示词都从零重新填充KV缓存 | 真正可用的聊天而非单次续写 |
stories42M | 量化后约21MB,仍在24MB堆内 | 更丰富的输出,相同UI |
stories110M | 放不下;需要从记忆棒流式读取权重 | 可能不值得承受吞吐量损失 |
限制不在于算力——VFPU升级能带来一个数量级的提升。限制在于RAM。64MB是预算,一旦为操作系统、堆、KV缓存和工作缓冲区付账之后,恰好只剩下一个17MB模型的空间,一个字节都不多。索尼发售这款硬件是为了播放MP3和运行Wipeout。这周我用过的其他所有LLM都跑在比PSP贵得多的GPU上。这个跑在PSP上。